Smart AI Blog Summary
Get a quick blog summary from any of the below LLM's
What You'll Learn
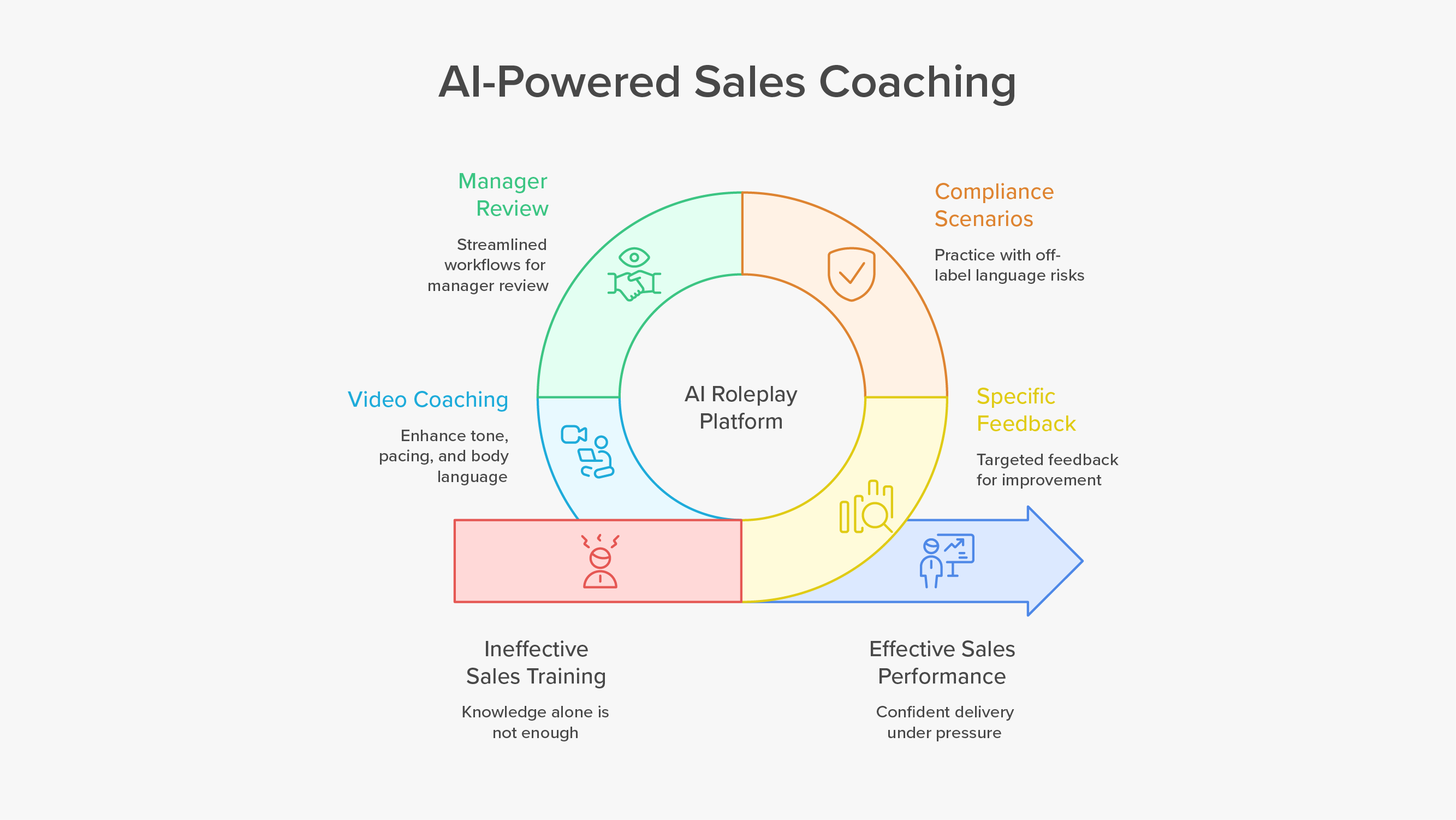
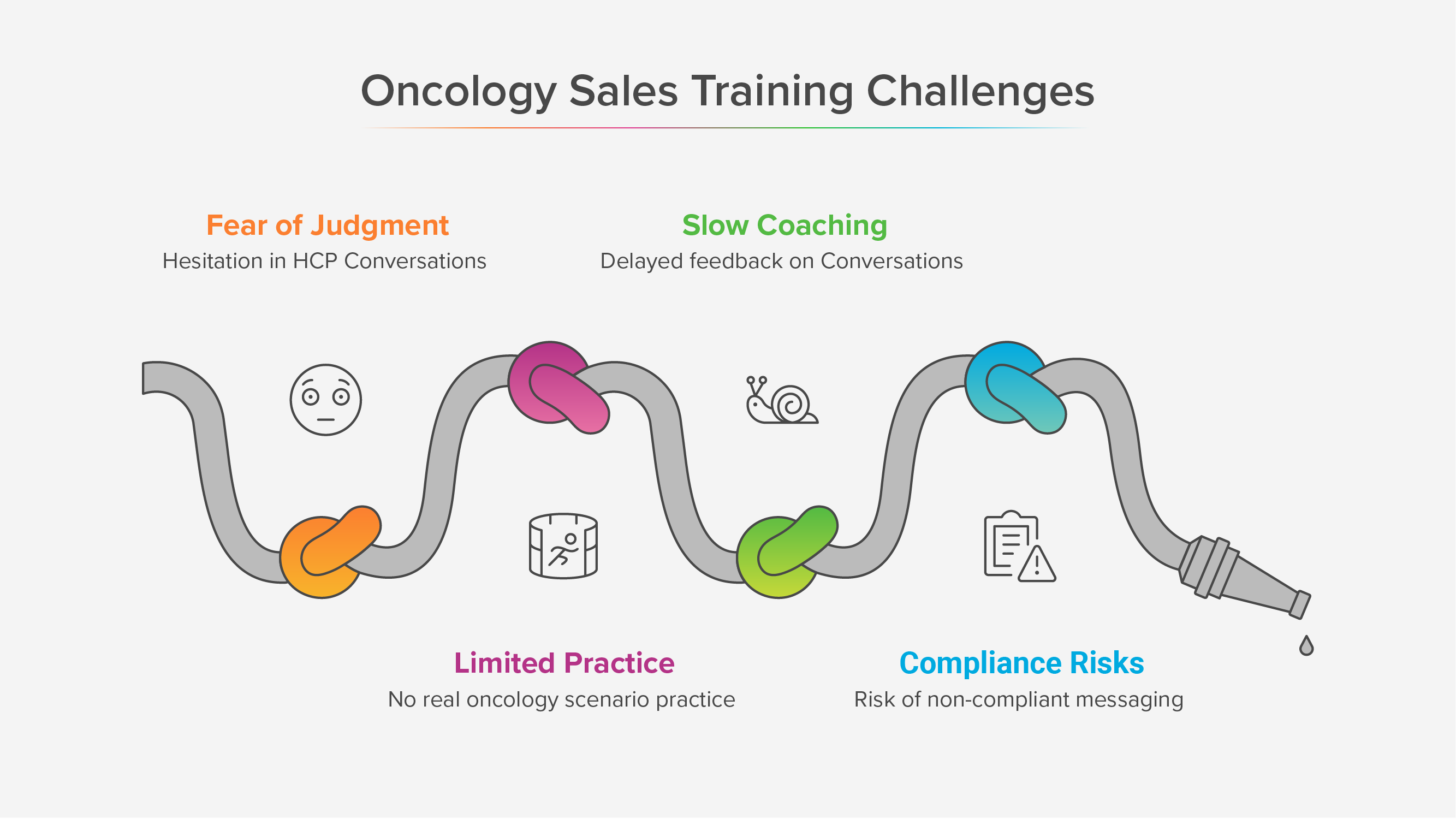
Sales leaders want AI Sales Roleplays that feel like real conversations, uphold compliance, and produce signals managers can coach from. You do not get there with models alone. You get there by putting domain experts in the loop at every step.
This article shows how to build a human-in-the-loop system that pairs your subject-matter expertise with the speed of AI. You will see where experts add the most value, how to structure a repeatable workflow, what to measure, and how platforms like SmartWinnr make the process practical at enterprise scale.
“The question is not when AI will match your best employees. It is how to use it effectively today, given its limits.”
Why domain experts matter in AI Sales Roleplays
Accuracy and compliance. Domain experts turn policy into practice. They encode label language, risk wording, and local constraints into scenarios and rubrics so reps practice the exact phrasing they must use. NIST’s AI Risk Management Framework calls this “human-AI configuration” and “oversight,” which means people must set boundaries and review outputs to manage risk.
Realism that earns trust. Experts know the tone, sequence, and pressure of real calls. They bring the buyer’s context, typical objections, and the way clinicians or procurement actually speak. When reps hear familiar pushback and timing, they trust the practice.
Fair, consistent scoring. Experts define weighted rubrics and pass gates. That removes guesswork. It also aligns with McKinsey’s finding that high-performing AI programs specify when model outputs need human validation.
Adoption across regions and roles. Expert review ensures scenarios respect regional policy, customer norms, and role nuance. That is how you scale without losing quality.
Faster improvement loops. Experts close the loop between the field and the lab. They turn new objections from real calls into next week’s scenario updates.
What “good” looks like: the anatomy of a quality roleplay
A strong AI Sales Roleplay has five parts:
Scenario brief that captures buyer type, objective, allowed sources, and red lines.
Dynamic turns that react to rep inputs, not a script.
Rubric and gates with clear weights for discovery, accuracy, objection handling, and required statements.
Actionable feedback that shows where the rep improved and what to fix first.
Analytics that roll up to team, region, and segment.
Expert involvement is the thread that keeps all five aligned. To add further, look for AI Sales Roleplays that don’t feel scripted and are dynamic.
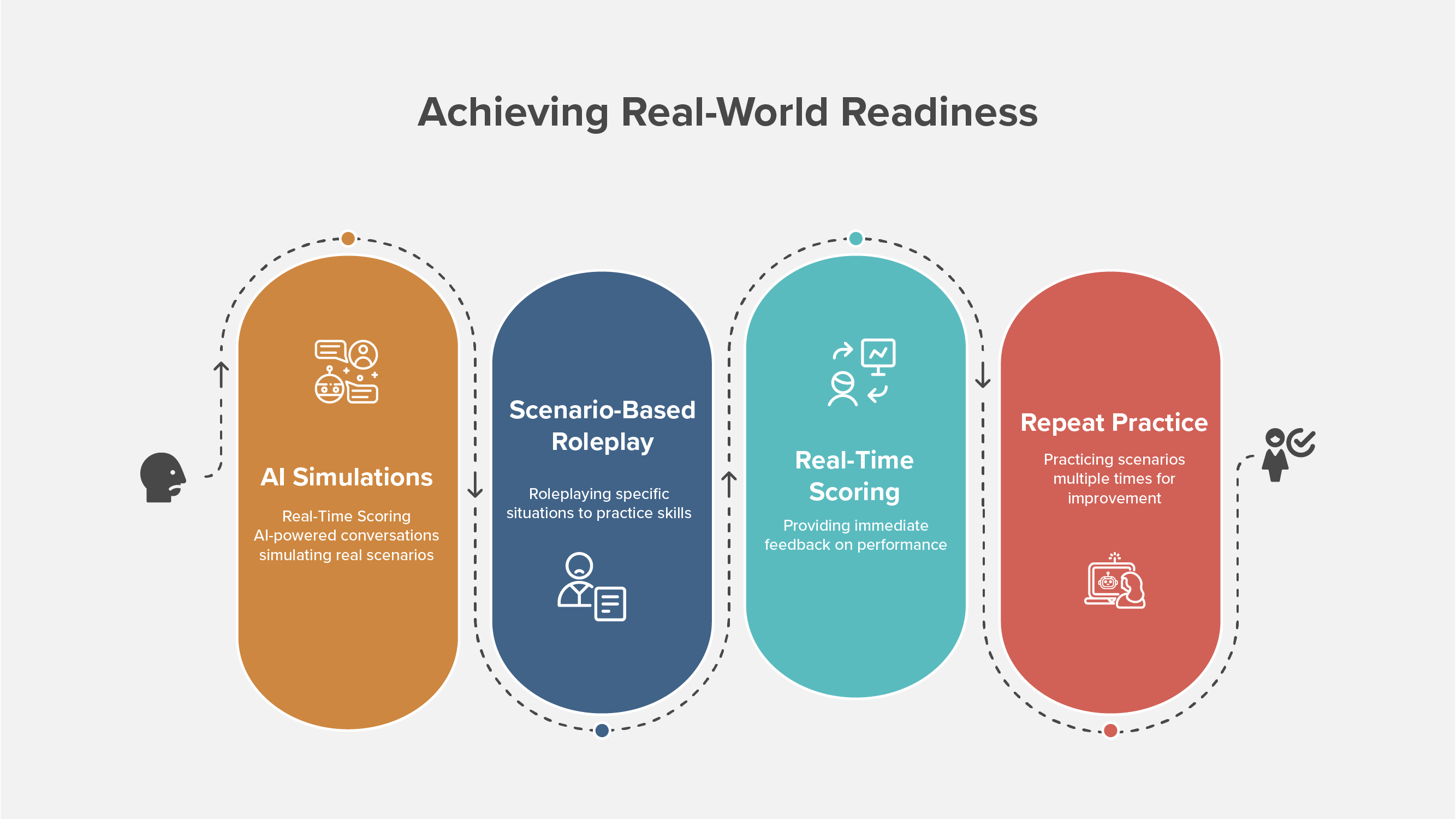
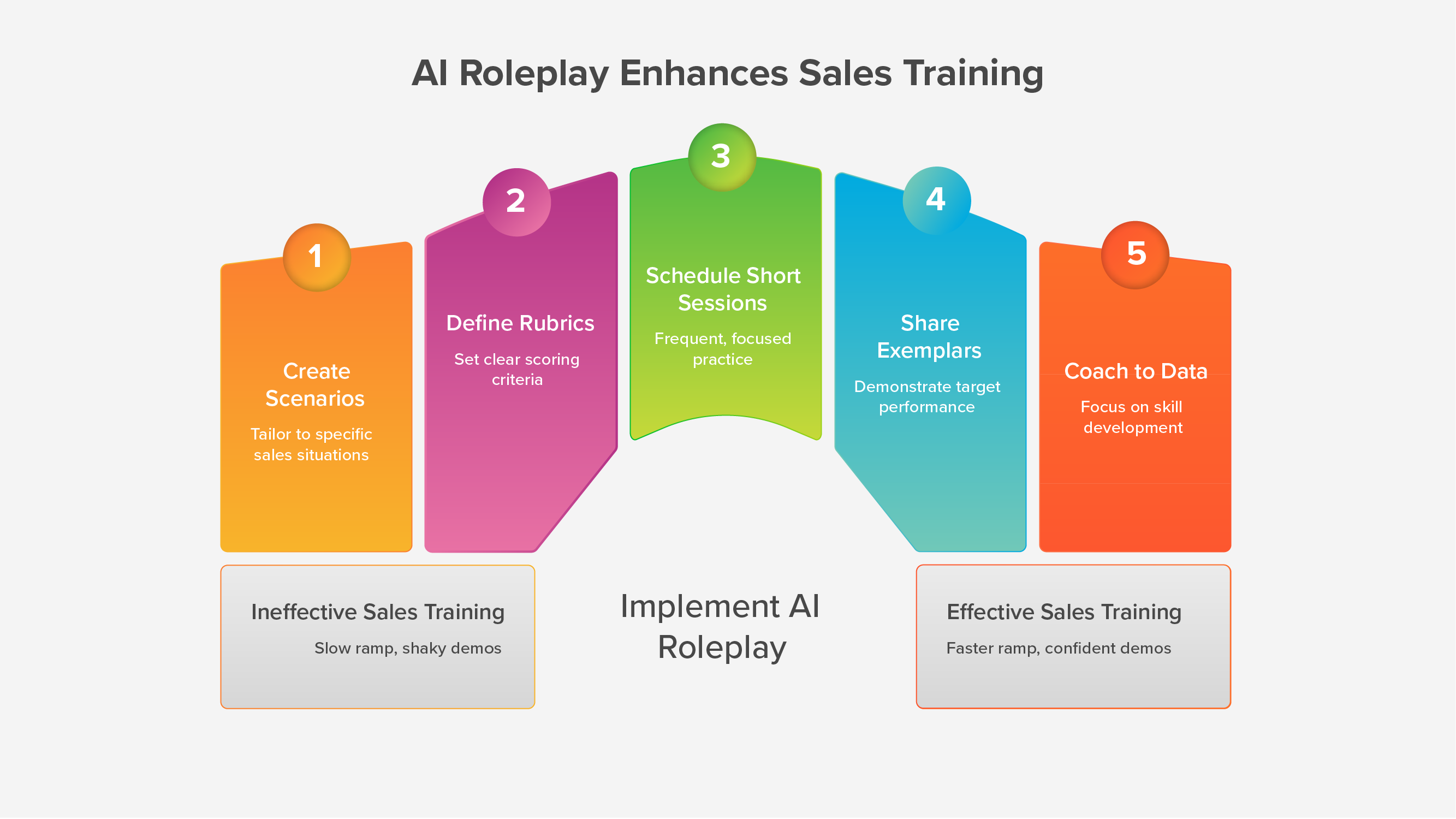
A practical human-in-the-loop workflow
Use a light, repeatable sprint that fits busy calendars.
Step 1: Intake (2 days)
Pick the top two conversations that affect outcomes right now.
Capture the scenario brief: purpose, buyer persona, evidence sources, compliance guardrails, success criteria.
Assign roles: business owner, domain reviewer, compliance reviewer, enablement lead, platform owner.
Step 2: Build and calibrate (3–5 days)
Draft prompts and objection banks from approved materials.
Set rubric weights and pass thresholds.
Run three calibration passes: expert, enablement, manager. Tighten language and flows.
Step 3: Pilot and tune (1 week)
Release to a pilot group.
Collect analytics: time to first pass, fail reasons, gate misses.
Experts update prompts and thresholds where confusion shows up.
Step 4: Roll out and govern (ongoing)
Publish standards and “what good looks like.”
Schedule quarterly rubric reviews with domain and compliance.
Keep an audit trail of changes and approvals.
NIST frames this as ongoing oversight and monitoring, not a one-time setup.
Rubrics that are fair, coachable, and auditable
Keep criteria observable and brief so managers can score while listening.
Uses four of five discovery prompts before solutioning.
States benefit and risk in one clear sentence when required.
Handles the objection using the team’s model within 20 seconds.
Delivers required statements in the correct order, no extra claims.
Closes on a next step that fits the customer’s goal.
Publish the pass threshold. Make certain items gates so a session cannot pass if a required statement is missing. This is where domain and compliance expertise protect the business while enabling speed.
The expert’s playbook for realism
Buyer voice: Write objections in the language your customers use.
Evidence targeting: Tie probes to the label, endpoints, or financial impact buyers ask about.
Context switches: Add follow-ups that force the rep to pause, clarify, and restate.
Escalation cues: Insert mild, medium, and hard versions of the same objection to test range.
Persona variance: Create variants for clinician, procurement, pharmacy, finance, or risk.
KPIs leaders will trust
Measure readiness and behavior change, not vanity numbers.
Time to first pass on priority scenarios.
Compliance gate pass rate in practice and random field audits.
Score by skill with clear green and red zones at team level.
Practice consistency across regions.
Field signal that matches your world: stage conversion, call-quality checks, or customer-satisfaction markers.
McKinsey notes that top AI performers redesign workflows and embed human validation where it matters. The KPIs above show that shift is happening and producing results.
Example patterns from the field
Launch readiness in life sciences. Experts weighted clinical accuracy and risk language as pass gates. Teams reached certification faster and audit findings dropped because the gates mirrored policy.
Rate and fee conversations in BFSI. Experts added clarifying questions customers actually ask. New reps reached confident delivery sooner because practice matched live pressure.
Complex device demos. Experts simplified the flow to three moves: headline, proof, check-back. Reps learned to handle interruptions and still land the point.
Notice the theme: realistic cues from experts plus clear scoring equals faster readiness.
Where a platform helps
SmartWinnr supports expert-in-the-loop design without adding overhead:
Two-way AI roleplays that adapt to rep inputs and are not scripted.
Weighted rubrics and pass thresholds for consistent grading.
Real-time suggestions that nudge better answers mid-practice.
Analytics and exemplars with top videos, transcripts, and keyword coverage so managers coach fast.
Modes for privacy and review so reps can practice without judgment and invite feedback when ready.
Scale for global teams with language support and tolerance for accents in English.
The result is a system where experts define “good,” AI delivers repetitions, and managers coach what matters.
Governance that keeps speed and safety together
Design authority: Domain and compliance own rubrics and gates.
Change control: Every scenario has version history and review dates.
Data hygiene: Use only approved sources in prompts and provide citations inside scenarios.
Oversight: Quarterly calibration with sample audits.
Clear roles: Business sets priorities. Experts set standards. Enablement runs the cadence. Managers coach.
This aligns with the human oversight guidance in NIST’s AI RMF and with operating patterns McKinsey sees in successful AI programs.
A one-week starter plan
Day 1: Choose two conversations that move the needle now. Draft briefs.
Day 2: Write objection banks and set rubric weights with domain and compliance.
Day 3: Build and run internal calibration.
Day 4: Pilot with one team.
Day 5–7: Tune based on analytics. Publish the cadence and thresholds.
Keep the loop tight. Ship, watch, adjust, repeat.
AI Sales Roleplays work best when domain experts set the guardrails and standards. Pair their judgment with a platform built for repetitions, transparent scoring, and clean analytics. You will get practice that feels real, coaching that targets the right moments, and readiness signals leaders can trust.
Disclaimer: This content reflects industry practices and does not constitute medical, legal, or regulatory advice.