Smart AI Blog Summary
Get a quick blog summary from any of the below LLM's
What You'll Learn
The best AI roleplays are not “set it and forget it.” They work when trainers, managers, and domain experts stay in the loop to shape scenarios, define scoring, review edge cases, and coach. That human layer is what turns simulations into reliable, compliant, and field-ready practice.
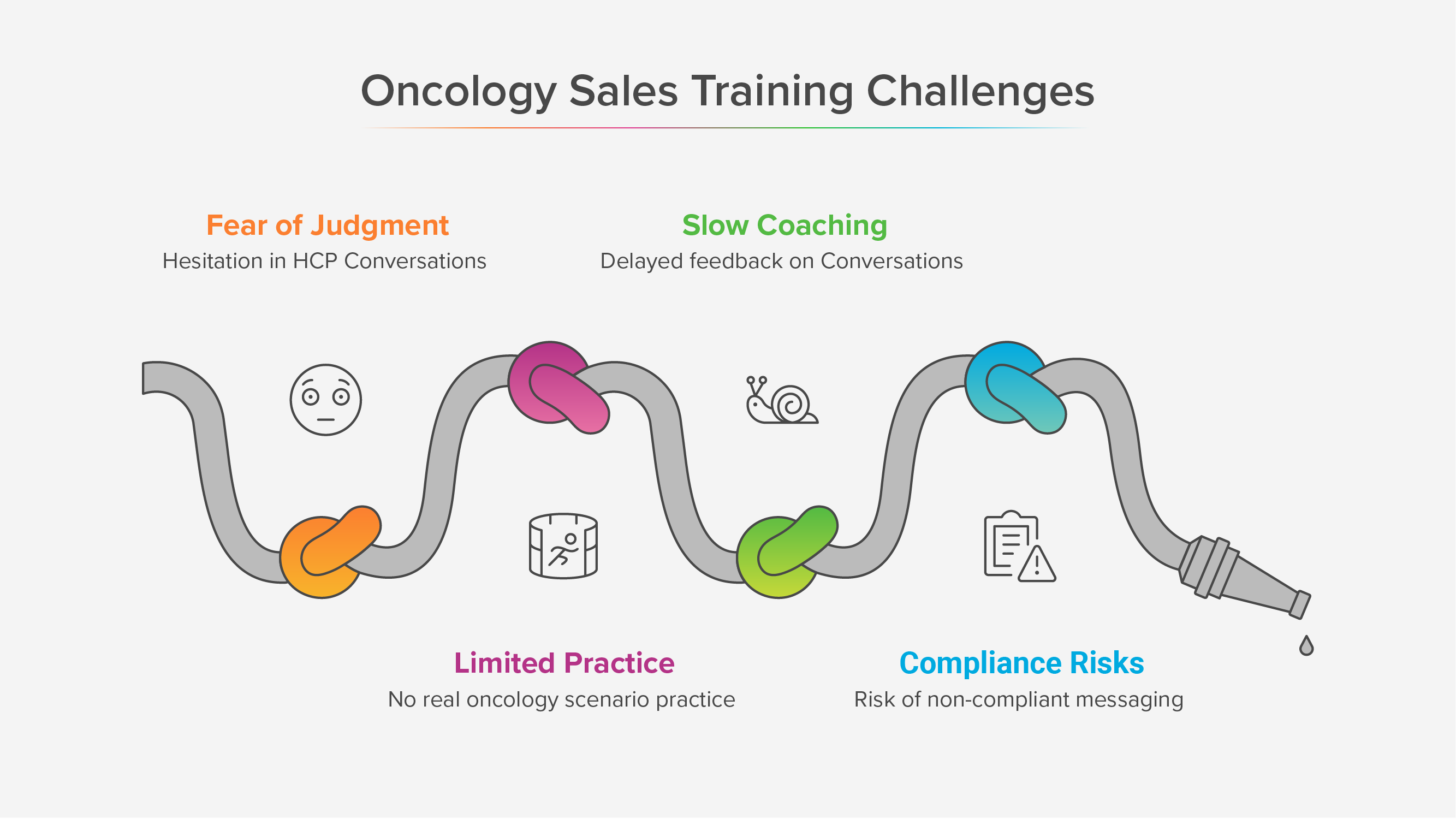
The problem AI roleplays are trying to solve
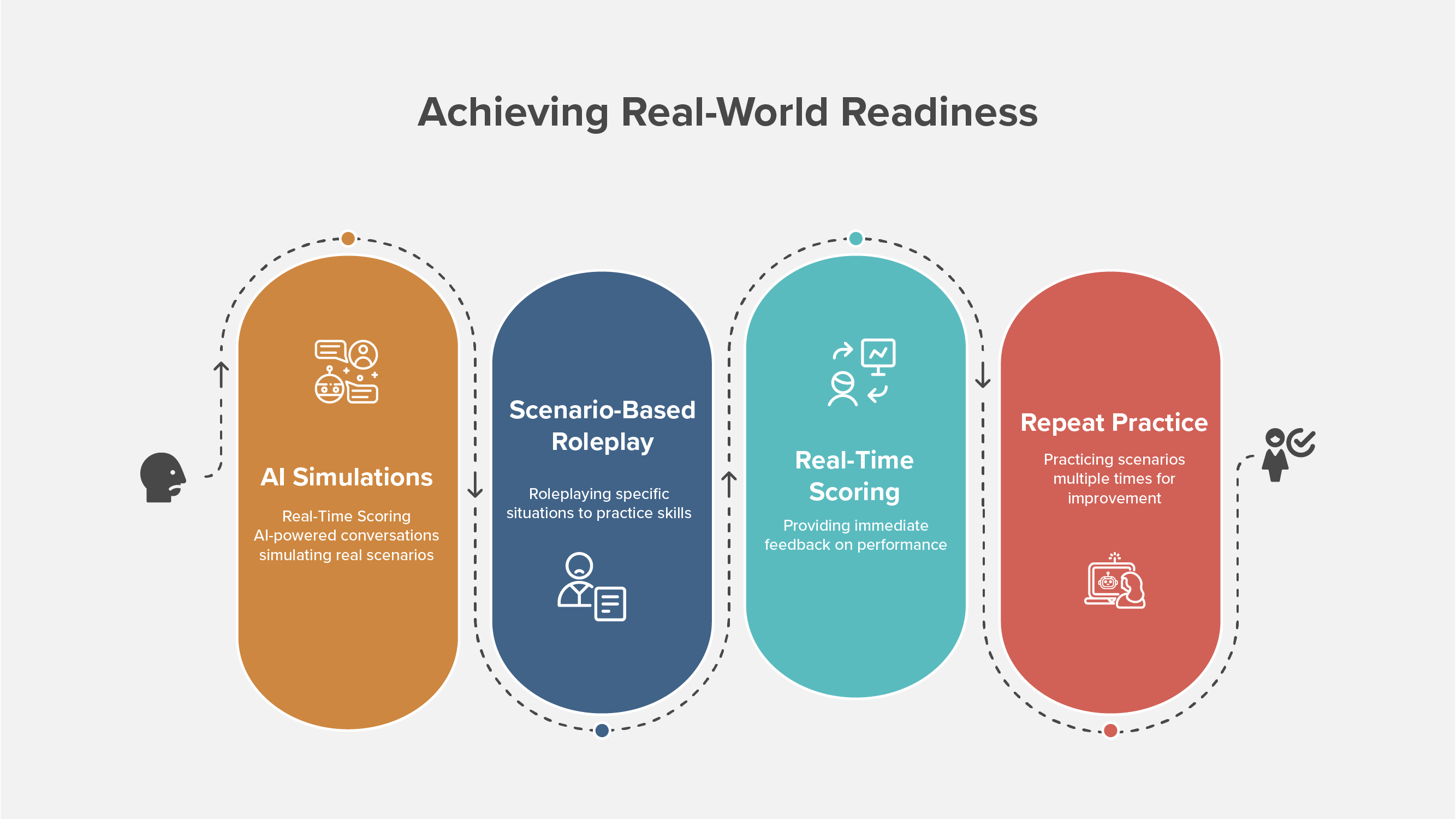
Sales teams learn the most when they practice real conversations. The catch is scale. You cannot run enough live roleplays for every new hire, product update, and objection. AI roleplays solve the volume problem by giving reps many short reps with instant feedback. That only sticks when the content feels real, the grading is fair, and the coaching stays consistent.
This is where human-in-the-loop matters. Humans decide what “good” looks like, what is compliant, and what deserves coaching time. AI provides repetitions and fast signals. Together they create a system that builds skill without adding meetings.
Two research notes back the approach:
Practice that forces recall improves retention more than review alone. This is the “testing effect.” (Karpicke & Roediger, Science, 2008).
Spaced practice strengthens memory more than cramming. (Cepeda et al., 2006 review).
Short, frequent, realistic reps with good feedback beat a single long workshop. Human-guided AI makes that possible at scale.
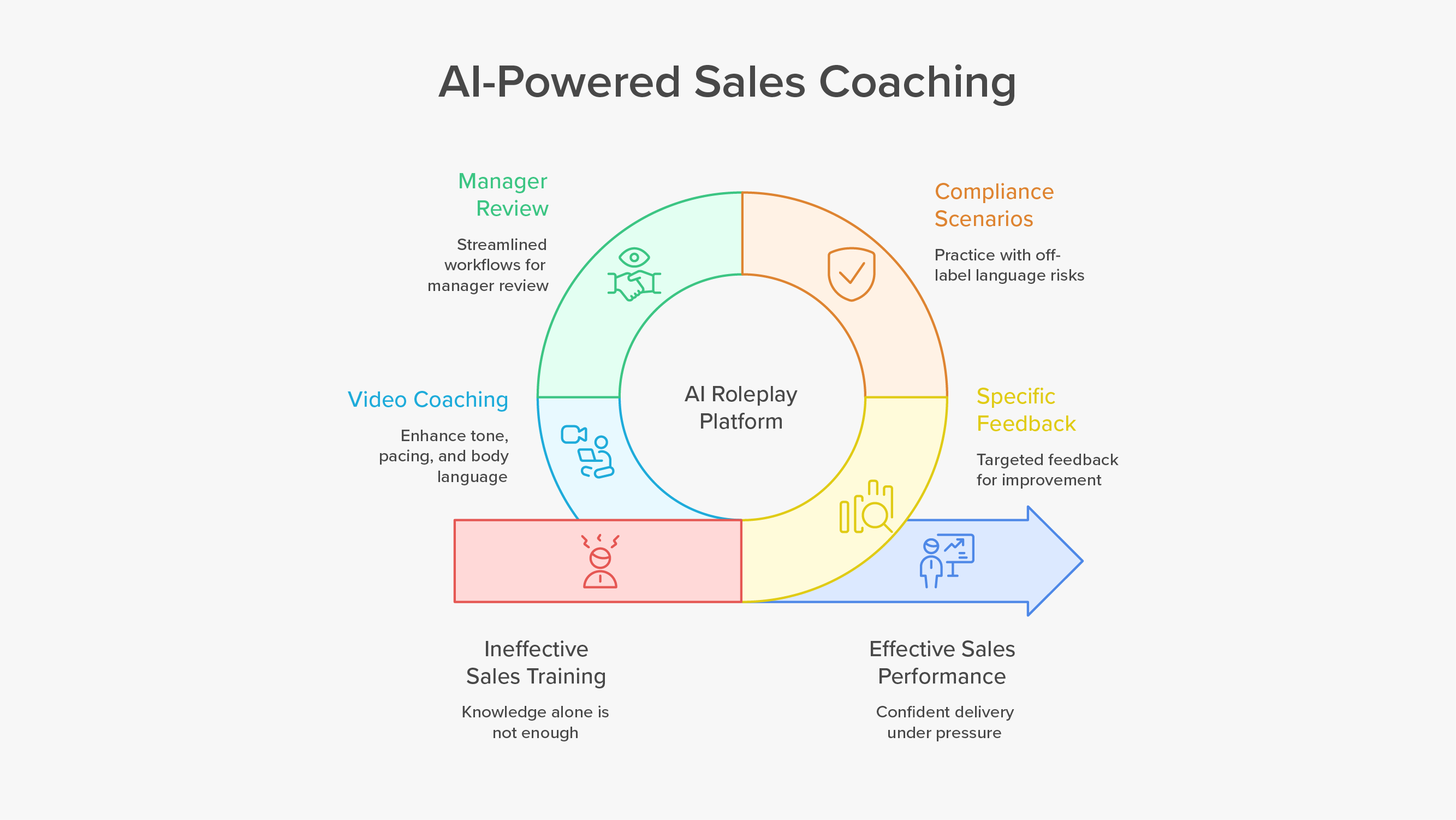
What “human-in-the-loop” actually means
Think about four points in the lifecycle of an AI roleplay program. People are essential in each.
Scenario design - Trainers and domain experts turn talk tracks, clinical decks, and objection banks into realistic conversations. They define buyer personas, required statements, and the questions a real stakeholder would ask. AI generates variety, but the guardrails come from people who know the work.
Rubrics and pass rules - Managers decide what “good” means. They weight criteria like discovery depth, clinical accuracy, value clarity, objection handling, and required disclosures. They set pass thresholds and non-negotiable gates. AI applies the rules and scores consistently across regions.
Coaching and exception handling - AI flags patterns and hotspots. Coaches decide what to fix first, which clip to study, and how to tailor feedback. They also catch edge cases the model might miss, then tune the rubric or scenario.
Governance and oversight - As models depend on content and content changes, someone must own monitoring and updates. NIST’s AI guidance calls for ongoing oversight, documentation, and post-deployment monitoring to manage risk and sustain trust.
When you remove people from any of these steps, quality drops. When you keep them in, quality scales.
Where a human-in-the-loop model beats end-to-end AI
Realism and trust.
Reps can tell when a scenario is generic. Human-curated prompts and personas keep the simulation close to the field. That builds buy-in and voluntary practice.
Fairness and consistency.
A published rubric with clear weights and pass gates earns trust. Humans define it. AI applies it the same way everywhere.
Compliance confidence.
In regulated settings, required lines and order matter. Humans codify the rules. AI enforces them every time, then humans audit the transcripts.
Change management.
Product labels change. Competitors move. Managers adjust scenarios and weights to match the quarter’s priorities. AI adapts fast once the direction is set.
Measurable coaching.
AI gives signals. Humans turn signals into action. A manager can look at two clips, leave two notes, and assign the next scenario. Coaching stops being a calendar problem and becomes a workflow.
What the data says about AI in commercial teams
Two signals worth noting:
LinkedIn’s 2024 sales research found 75% of sellers who exceeded quota used AI tools, while only 54% of under-quota sellers did. That points to AI as a performance multiplier when used well.
McKinsey’s 2023 analysis estimates that generative AI could add $2.6T to $4.4T in value annually across functions like sales, marketing, and customer operations. The takeaway is simple. The upside is large, but only if the work is operationalized with human oversight.
NIST’s AI Risk Management guidance reinforces the pattern: align oversight with risk, monitor after deployment, and keep humans in the loop for decisions that carry impact.
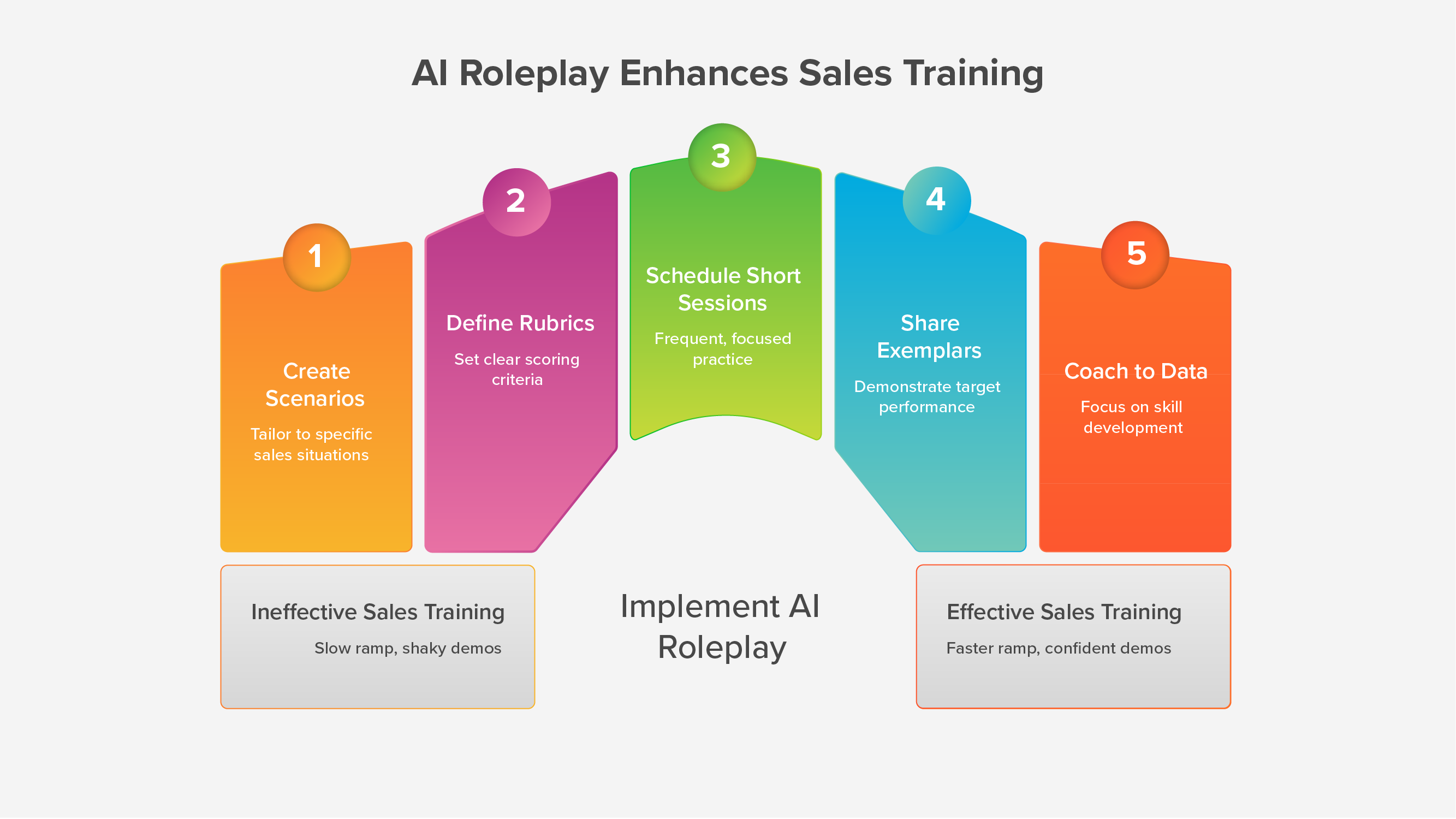
How to run Human-in-the-loop roleplays that reps actually use
Here is a practical setup you can run with a small team.
1) Start with four scenarios
Discovery with a five-prompt ladder.
Screen-guided demo limited to three key screens.
Top objection with a shared answer model.
Compliance or policy step with pass gates.
2) Publish a simple rubric
Criteria: discovery depth, accuracy, value clarity, objection handling, call control, required statements.
Weights: make the quarter’s priorities visible.
Pass rules: if compliance lines are missing or out of order, it does not pass.
3) Set a weekly rhythm
Three short sessions per rep.
Two micro-lessons or quizzes when messaging changes.
One manager touch that follows the two-clip rule: one highlight, one hotspot, two notes, one next step.
4) Keep sessions under ten minutes
Short reps fit between meetings, which drives consistency. Retrieval practice and spacing do the rest.
5) Measure what leaders care about
Time to first pass on the priority scenario.
Score by skill with clear red and green.
Practice consistency per rep.
One field signal that fits your world, such as stage conversion or audited call quality.
6) Close the loop every Friday
A 20-minute “win room.” One exemplar clip. One pattern to fix next week. One small change to the rubric or scenario if needed.
What stays with humans, what you let AI handle
Keep with humans
Scenario intent and persona realism
Rubric weights and pass thresholds
Coaching choices and next steps
Compliance review of required lines
Keep with AI Sales Roleplay
Scoring at scale using the rubric
Immediate feedback and transcripts
Keyword coverage and time-to-answer
Leaderboards and certification tracking
This division of labor is simple. People define the target and the change plan. AI makes practice and measurement repeatable.
Examples that map to real teams
Pharma onboarding
New reps practice an HCP discovery, an evidence conversation, a safety statement sequence, and a short demo. Required lines are hard gates. The team reports faster certification and cleaner audit trails. Managers stop grading by hand and spend time coaching tough objections.
Associates rehearse KYC interviews, risk and suitability, and fee objections. Pass thresholds are strict for disclosures. Branch leaders get a dashboard that shows who is ready for live interviews and who needs one more round on suitability questions.
In both cases the model is the same. Humans keep it real and fair. AI carries the repetition and the scoring load.
Governance without the headache
You do not need a new committee to do this well. You need a light process that runs every month.
Review one scenario and its pass data.
Sample ten transcripts for compliance phrasing.
Update weights based on the quarter’s focus.
Retire one scenario and add one new one.
Track model drift by watching false flags or misses. NIST recommends post-deployment monitoring for exactly this reason.
Keep the notes in one shared doc. Trainers and managers should be able to explain changes in one slide.
The bottom line
Human-in-the-loop is not a slogan. It is the operating model that makes AI roleplays effective. People set standards. AI scales practice. Coaches focus on what matters. Leaders get signals they can trust.
If you keep humans in the loop at scenario design, scoring rules, coaching, and governance, your AI roleplays will feel real, stay compliant, and improve calls in the field.
Disclaimer: This content reflects industry practices and does not constitute medical, legal, or regulatory advice.